
1. Dilemma and Breakthrough: Why Human-Designed Algorithms Can’t Compete with Machine Evolution?
Reinforcement Learning (RL), the “engine” behind AI’s autonomous decision-making, has long been trapped in an “human bottleneck.” From the policy gradients of AlphaGo to the planning framework of MuZero, every iteration of RL algorithms relies on the inspirational collaboration of top experts. This process not only takes years but also struggles to adapt to complex scenarios such as sparse rewards and partially observable environments. When integrating short-term reactions with long-term planning in Atari games or navigating unknown mazes in NetHack, human-designed algorithms often fail to balance competing demands.
In October 2025, a study published by Google DeepMind in Nature offered a solution: the DiscoRL method, developed by David Silver’s team, enables AI to independently discover RL rules through meta-learning. Its performance not only surpasses state-of-the-art (SOTA) algorithms designed by humans but also ushers in a new paradigm of “machine-created algorithms.” This breakthrough is regarded by the industry as a milestone marking RL’s transition from “human-driven iteration” to “autonomous evolution.”
2. Dual-Loop Optimization: The Core Technical Logic of DiscoRL
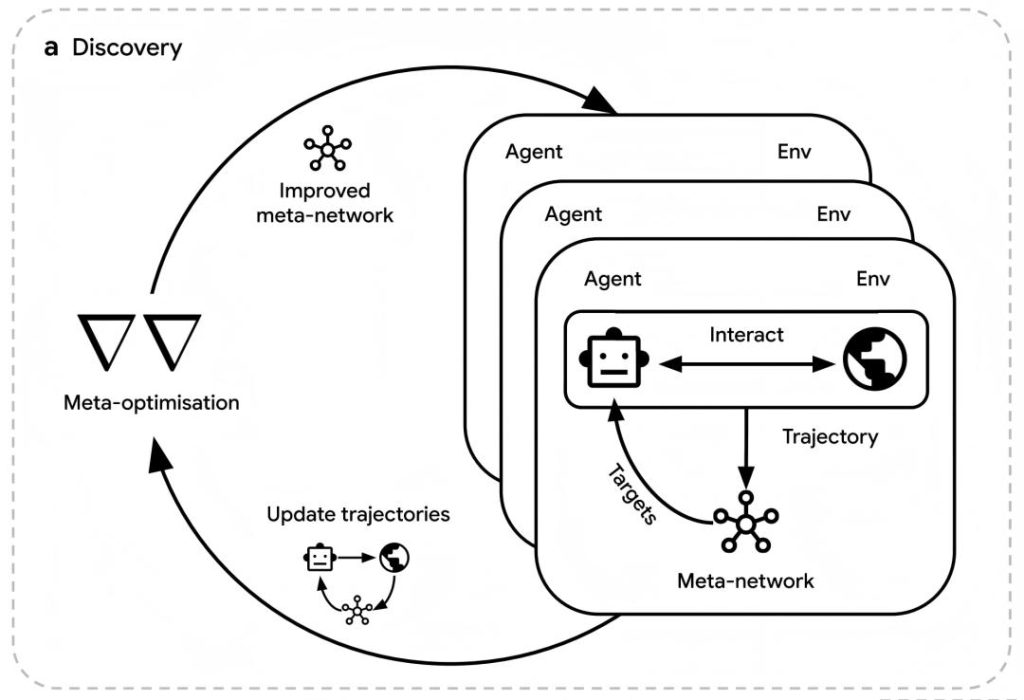
The revolutionary nature of DiscoRL lies in its construction of a “agent learning – meta-rule evolution” dual-loop optimization system, which completely breaks free from reliance on human presets.
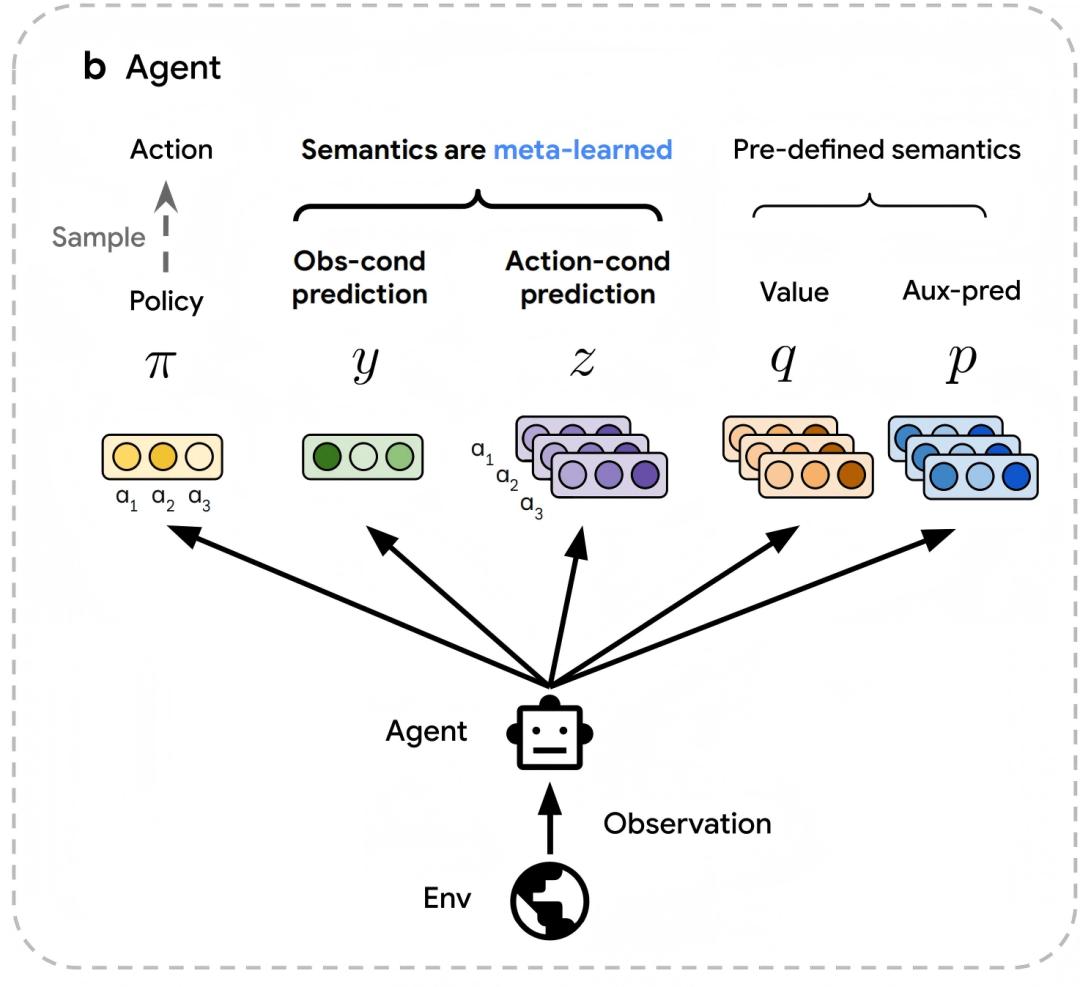
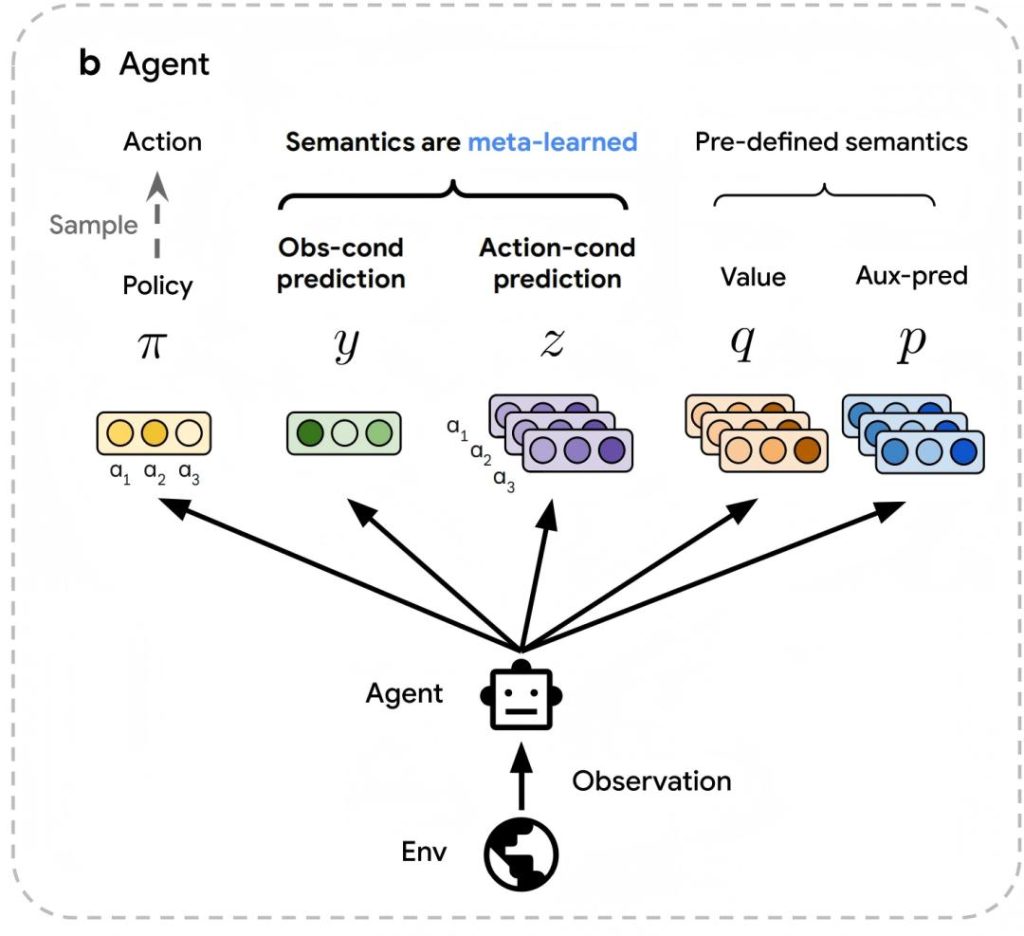
Agent Layer: Ambiguous Predictions Unlock the Algorithm Space
Unlike traditional RL, which predefines value functions and loss functions, DiscoRL designs a prediction system without semantic constraints. The agent, controlled by parameter θ, not only outputs a policy π but also generates two core types of predictions: an observation-based vector y(s) and an action-based vector z(s,a). This design draws on the inherent distinction between “prediction” and “control”—similar to the division of labor between state value v(s) and action value q(s,a)—but is not limited to existing concepts, reserving space for the discovery of entirely new algorithmic components. Meanwhile, the agent retains basic predictions such as action value q(s,a) as “anchors” to guide meta-learning toward innovative breakthroughs.
Meta-Network Layer: Trajectory Data Drives Rule Evolution
The meta-network serves as DiscoRL’s “algorithm designer,” with its core task being to extract optimization rules from the agent’s interaction trajectories. It processes trajectory data (including predictions, policies, rewards, etc.) from time steps t to t+n using an LSTM network and outputs target values (π̂, ŷ, ẑ) that the agent needs to approximate. This “forward view” design inherently inherits the bootstrapping concept of traditional RL while offering three key advantages: adapting to any observation space by indirectly receiving agent predictions; decoupling from the agent’s architecture to generalize across different model scales; and outputting target values (rather than scalar losses) to include semi-gradient methods in the search space.
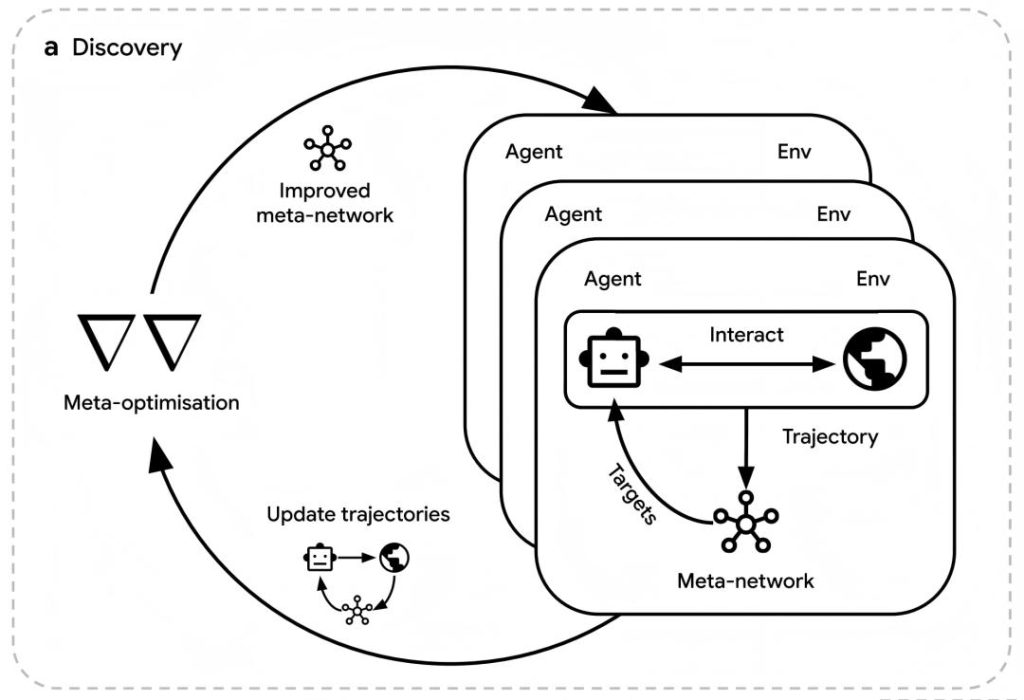
Dual-Loop Linkage Mechanism
The agent updates its parameter θ by minimizing the gap between its outputs and the meta-network’s targets using Kullback-Leibler (KL) divergence. The meta-network, in turn, optimizes its meta-parameter η through gradient ascent to maximize the cumulative rewards of the agent cluster. To improve efficiency, the research team used 20-step sliding window backpropagation to estimate meta-gradients and introduced a meta-value function to assist in advantage calculation, enabling the dual-loop optimization to operate efficiently in large-scale environments.
3. Data Speaks: Comprehensive Superiority from Atari to NetHack
DeepMind’s experiments across 103 complex environments confirmed DiscoRL’s performance and generalization capabilities.
Absolute Advantage in Benchmark Tests
Disco57, a rule trained on 57 Atari games, set a new record on this benchmark with an Interquartile Mean (IQM) score of 13.86, outperforming classic algorithms such as MuZero and Dreamer. More critically, it achieved a breakthrough in efficiency: Disco57 reached optimal performance with only approximately 600 million steps per game, equivalent to the cost of 3 experimental rounds. In contrast, human-designed algorithms typically require dozens of iterations and months of debugging.
Remarkable Cross-Environment Generalization
In the unseen ProcGen benchmark (16 procedurally generated games), Disco57 still outperformed SOTA algorithms like PPO. It demonstrated competitive performance in Crafter—an environment requiring integrated survival skills—and even secured third place in the NetHack NeurIPS 2021 Challenge, which involved over 40 teams. Notably, it achieved this without using any domain-specific knowledge. By comparison, an IMPALA algorithm configured identically performed poorly, confirming the superiority of autonomously discovered rules.
The Evolutionary Code of Environmental Diversity
When the training environment was expanded to 103 tasks (combining Atari, ProcGen, and DMLab-30 benchmarks), the newly generated Disco103 rule showed further improvements: it reached human-level performance in Crafter and approached MuZero’s SOTA performance in Sokoban while maintaining similar performance on Atari. In contrast, a control group rule trained on 57 simple grid-world tasks (extended from previous work) showed a sharp decline in performance on Atari tests (see Figure c), proving that “feeding on complex environments” is the core fuel for algorithmic evolution.
4. Industrial Implications of Autonomous Algorithmic Evolution
The significance of DiscoRL extends far beyond a single technical breakthrough; it brings three transformative changes to AI R&D models:
Exponential Improvement in R&D Efficiency
Traditional RL algorithm development follows a lengthy cycle of “theoretical derivation – experimental validation – iterative modification.” In contrast, DiscoRL can automatically generate optimal rules with only computational resources and environmental data input. Its training cost of 600 million steps per game is a “dimension-reducing blow” compared to the years of effort required from human experts.
A Progressive Path to Artificial General Intelligence (AGI)
This study confirms that RL rules can emerge autonomously through environmental interaction, rather than relying on human understanding of “intelligence.” As environmental diversity and computing power increase, DiscoRL is expected to discover more general learning paradigms, providing foundational support for the realization of AGI.
Accelerated Deployment of Industrial Applications
In complex scenarios such as robot control and autonomous driving, environmental dynamics and task requirements often change with the scenario. DiscoRL’s autonomous evolution capability allows real-time adaptation to new environments without the need for human-led algorithm redesign, clearing a key barrier to industrial-scale RL applications.
Conclusion: The Dawn of the AI-Creates-AI Era
DiscoRL’s breakthrough is not an end. Through gradient analysis, the research team found that its prediction vectors y(s) and z(s,a) can capture “predictive information” not covered by policy and value functions—such as upcoming high rewards and changes in policy entropy. The discovery of these new algorithmic components suggests that machines’ understanding of “learning” has begun to surpass that of humans.
When AI can not only execute tasks but also independently design the “methodology” for task execution, the evolution of artificial intelligence will enter a new phase of self-acceleration. With DiscoRL, DeepMind has proven that the future of AI R&D may no longer require human programmers to labor over formula derivations; instead, machines will find their own path to becoming “smarter versions of themselves” in the ocean of data.





